챗지피티 대화내역, 업무데이터 보호 방법 (ChatGPT, 챗GPT)

앞서의 글들에서 챗지피티를 통한 업무 기밀의 유출에 대해 알아보았습니다. 이번 글에서는 챗지피티가 사용자의 입력 정보, 데이터를 학습하는 방법과 챗지피티가 사용자 데이터를 학습하는 것을 막는 방법에 대해 알아보도록 하겠습니다.
챗지피티 사용자 대화내역 / 데이터 학습 방법
챗지피티는 입력된 데이터를 기반으로 모델 성능을 향상시키기 위해 학습합니다. 사용자가 입력한 질문과 챗지피티가 제공한 응답을 분석하여, 모델의 정확성과 유용성을 높이는 데 사용됩니다. 이 과정은 주로 다음과 같은 단계로 이루어집니다.
- 데이터 수집: 사용자가 챗지피티와 상호작용할 때 입력된 모든 데이터는 수집됩니다. 여기에는 텍스트 대화, 질문, 응답 등이 포함됩니다. 수집된 데이터는 모델의 성능을 평가하고 개선하는 데 필수적인 역할을 합니다.
- 데이터 전처리: 수집된 데이터는 분석 전에 전처리 과정을 거칩니다. 이 과정에서 불필요한 정보나 노이즈가 제거되고, 데이터가 분석 가능한 형식으로 변환됩니다. 전처리된 데이터는 학습 알고리즘에 입력되기 전에 클리닝 및 정제 과정을 거칩니다.
- 모델 학습: 전처리된 데이터는 챗지피티의 학습 알고리즘에 입력됩니다. 모델은 새로운 데이터를 통해 패턴을 학습하고, 이를 바탕으로 더 정확한 응답을 생성하는 능력을 갖추게 됩니다. 이 과정에서 모델은 기존 데이터와 새로운 데이터를 통합하여 학습합니다.
- 성능 평가: 학습된 모델은 다양한 테스트 데이터셋을 통해 성능 평가를 받습니다. 이 평가 결과를 바탕으로 모델의 강점과 약점을 분석하고, 필요한 경우 모델을 수정하거나 재학습시킵니다. 성능 평가 과정은 모델의 지속적인 개선에 중요한 역할을 합니다.
- 피드백 루프: 사용자의 피드백은 모델 개선에 중요한 데이터를 제공합니다. 사용자가 챗지피티의 응답에 대해 제공하는 피드백은 모델의 학습 과정에 반영되어, 더 나은 성능을 발휘할 수 있도록 합니다. 피드백 루프는 지속적인 학습과 성능 개선의 핵심 요소입니다.
이와 같이 챗지피티는 개인이 입력한 데이터를 바탕으로 학습하며, 이를 통해 모델의 성능을 지속적으로 개선합니다. 하지만 사용자가 입력하는 데이터가 민감하거나 개인 정보일 경우, 이를 보호하기 위한 조치가 필요합니다.
보다 자세한 설명을 OpenAI로부터 확인하시기 위해서는 아래 버튼을 이용하시기 바랍니다.
| OpenAI의 데이터 학습 방법 확인하기 > |
챗지피티의 사용자 대화내역 / 데이터 학습으로부터 데이터 보호 방법
OpenAI는 사용자에게 데이터 학습 금지 설정을 제공합니다. 사용자는 자신의 데이터가 모델 학습에 사용되지 않도록 요청할 수 있습니다. 이를 위해 OpenAI의 고객 지원팀에 문의하거나, ChatGPT 설정에서 "Chat history & training" 옵션을 비활성화하면 됩니다. 이 설정을 통해 대화 내역이 모델 학습에 사용되지 않으며, 대화 내용은 30일 후 영구 삭제됩니다.
대화 내역을 모델 학습에 사용하지 못하도록 설정하는 방법은 다음과 같습니다.
- 우측 상단 프로필의 설정을 선택합니다.
- 설정의 좌측 데이터 제어 탭에서 '모두를 위한 모델 개선'을 선택하여 꺼짐으로 바꿉니다.
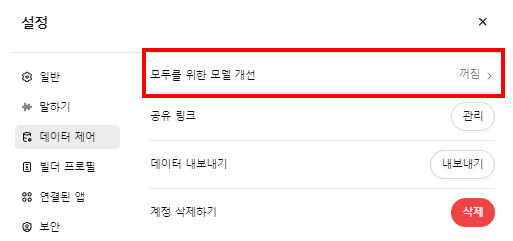

'모두를 위한 모델 개선'은 사용자가 작성, 입력하는 내용들을 챗지피티가 학습하여 향후 다른 사용자들의 답변에도 활용한다는 의미입니다. 이것을 비활성화해두면 사용자가 입력하는 내용들을 챗지피티가 학습하지 않기 때문에 기밀 유출에 대한 우려도 사라지게 됩니다.
'ChatGPT' 카테고리의 다른 글
| [19] 챗지피티 달리3 프롬프트 작성방법 / 달리3 사용법 / 달리3 저작권은 누구 소유? (DALL-E 3) (0) | 2024.07.19 |
|---|---|
| [18] 챗지피티 DALL-E 사용법 (초보용), 주요기능, 이미지 생성원리 (2) | 2024.07.19 |
| [16] 챗지피티 보안 위험요소 / 올바른 챗지피티 사용법 / 챗지피티 보안 강화 방법 (삼성전자 사고 사례) (1) | 2024.07.15 |
| [15] 챗지피티 오류 원인과 해결방법 알아보기 (챗지피티 먹통) (0) | 2024.07.12 |
| [14] 챗지피티 표절 피하는 방법 / 챗지피티 결과물이 표절 걸리는 이유 (0) | 2024.07.05 |



